Apache Parquet 格式简介
简介
Parquet 是一种面向列的数据存储格式,在 Hadoop 生态中使用广泛。Parquet 文件是不可变的,如果需要修改,只能通过 rewrite 的方式实现。
数据 layout
一个 Parquet 文件的数据布局如下图所示。需要注意的是,官网上的这个图并没有包含 index pages。




在 Parquet 中,数据每隔若干行被分作一个 row group;在同一个 row group 中,不同 row 的相同列被连续存储在一起。连续的列再间隔若干行会被分割为一个页(page)。
元数据
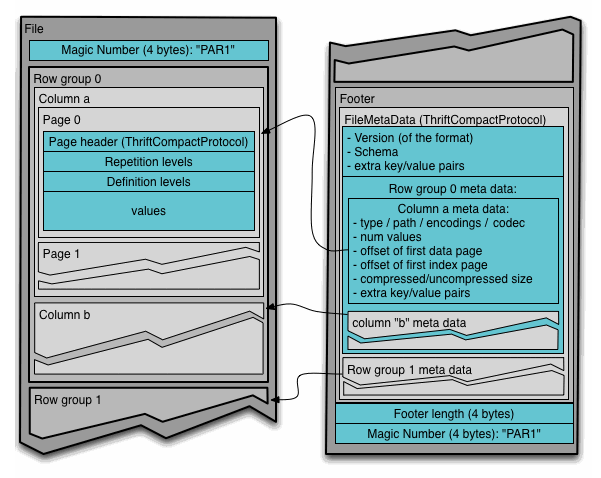
从如上的 Parquet 格式可以看出来,一个 Parquet 文件是包含了一些元数据的,比如 footer、page header 等等,这些元数据可以在读取 parquet 文件的时候提供相关信息来加速遍历。
Footer
Footer 是整个 Parquet 文件的元数据,从 footer 可以得到文件的版本、数据 schema、row group 的元数据、row group 中的每一列的元数据等等。
Footer 位于 Parquet 的末尾,因此可以从文件结尾 seek 到倒数第 8 到倒数第 4 字节,作为 footer 的长度,从而得到 footer 区的起始 offset。
Footer 区数据遵循特定的编码格式(ThriftCompactProtocol),因此可以方便地反序列化。
Footer 区还包含了 row group 和 row group 中的列的信息。
列的元数据
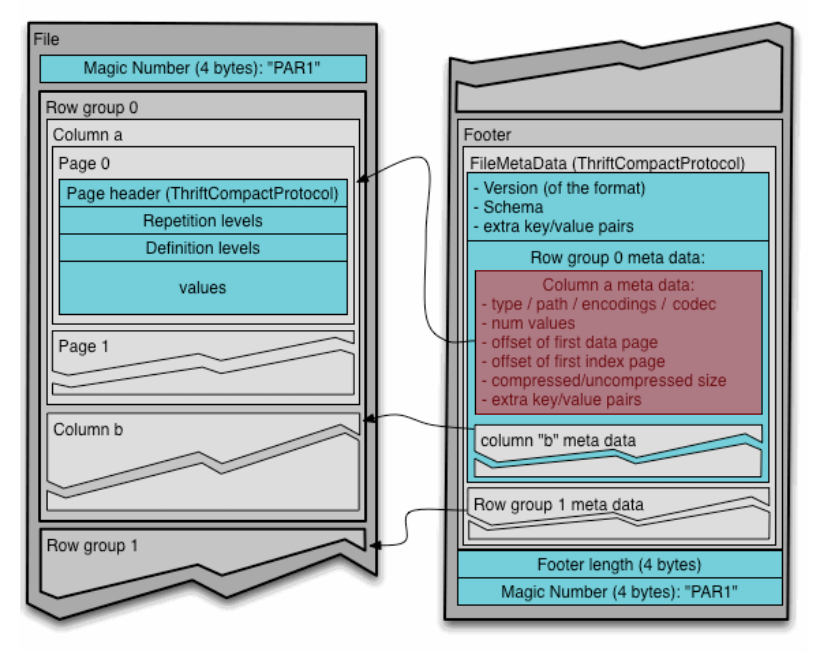
在 footer 中,每一列的信息也被记录,包括:
- 列的类型、编码;
- 列值的数量;
- 第一个数据页的 offset;
- 第一个索引页的 offset;
- 压测/解压缩的大小;
- 以及一些额外的键值对。
根据 footer 中的这些列的信息就可以快速找到 Parquet 文件中的数据地址和索引地址、以及如何解析这些数据。
文件内索列
Parquet 2.5 版本支持了列值索引功能,具体的功能介绍可以参考 ColumnIndex Layout to Support Page Skipping.
在之前的版本中,统计数据(min、max)只在 column 的 metadata 和 page header 当中,当读取 page 的时候,可以根据 page header 中的统计数据决定是否需要跳过这一页,但这样还是需要遍历文件中的每一页。
目标:通过 minmax 可以直接定位到 page 的方式提高范围查询和点查的 IO 效率。具体来说针对 row group 排序列的单行查询,每一列只需要读取一页数据。排序列的范围查询只读取范围所涉及的数据页;如果其他的查询具有高选择性,即使查询条件不是排序列,也要能够按需读取数据页。
为了实现这样的目标,Parquet 在 row group 的元数据上增加了如下两个针对列的数据结构(即在一个 row group 中的每一个列都有下面的两个索引来描述它们):
- ColumnIndex:针对 scan predicate,支持通过列值找到列的数据所在的页;
- OffsetIndex:通过 ColumnIndex 找到 match 的 row 之后,OffsetIndex 支持按 row index 去获取相应的值。一个 row group 的所有 column 的 OffsetIndex 都是存储在一起的。
索引的地址在 footer 区之前的地方,footer 里面有一个字段指明了其 offset。

/// Description for ColumnIndex.
/// Each <array-field>[i] refers to the page at OffsetIndex.page_locations[i]
#[derive(Clone, Debug, Eq, Hash, Ord, PartialEq, PartialOrd)]
pub struct ColumnIndex {
/// A list of Boolean values to determine the validity of the corresponding
/// min and max values. If true, a page contains only null values, and writers
/// have to set the corresponding entries in min_values and max_values to
/// byte[0], so that all lists have the same length. If false, the
/// corresponding entries in min_values and max_values must be valid.
pub null_pages: Vec<bool>,
/// Two lists containing lower and upper bounds for the values of each page.
/// These may be the actual minimum and maximum values found on a page, but
/// can also be (more compact) values that do not exist on a page. For
/// example, instead of storing ""Blart Versenwald III", a writer may set
/// min_values[i]="B", max_values[i]="C". Such more compact values must still
/// be valid values within the column's logical type. Readers must make sure
/// that list entries are populated before using them by inspecting null_pages.
pub min_values: Vec<Vec<u8>>,
pub max_values: Vec<Vec<u8>>,
/// Stores whether both min_values and max_values are ordered and if so, in
/// which direction. This allows readers to perform binary searches in both
/// lists. Readers cannot assume that max_values[i] <= min_values[i+1], even
/// if the lists are ordered.
pub boundary_order: BoundaryOrder,
/// A list containing the number of null values for each page *
pub null_counts: Option<Vec<i64>>,
}
#[derive(Clone, Debug, Eq, Hash, Ord, PartialEq, PartialOrd)]
pub struct OffsetIndex {
/// PageLocations, ordered by increasing PageLocation.offset. It is required
/// that page_locations[i].first_row_index < page_locations[i+1].first_row_index.
pub page_locations: Vec<PageLocation>,
}
Parquet 的优势
- 按需读取列的值,比如在 OLAP 场景下,大宽表往往最终只有少量的列会被读取到;
- 自描述,自带 schema,支持数据结构嵌套;
- 由于列保存在一起,因此可以提高压缩和编码的效率(比如 RLE、字典压、Bit Packing 等等);
- 文件自带索引,支持快速检索 data page。