Apache BookKeeper 笔记
BookKeeper 的使用场景
- WAL:比如 HDFS Namenode 的 EditLog(要求高可靠)
- 分布式存储:比如 Pulsar 的消息存储、DistributedLog 等
核心理念
- 通过条带化写(Data Striping)实现数据的多副本,所有存储节点角色对等;
- 通过其他的存储组件(ZooKeeper)实现元数据高可靠,故障恢复(recover)流程强依赖 ZK 的元数据;
- 也可以选用其他的存储服务,要求 1. CP 系统;2. 提供 CAS 原语
- 基于 RocksDB 提供
(ledger, sequence) -> (file, physicalOffset)的索引(SingleDirectoryDbLedgerStorage#ledgerIndex); - 同一时刻只有一个 writer 和多个 reader,通过 fencing 机制避免出现多 writer,避免 sequence 乱序;
- 读写分离,冷热分离(tailing read/catch-up read)提高吞吐;
BookKeeper 的术语
- ledger:一写多读的 append-only 文件,ledger 的最小数据单元是 fragment;
- bookie:存储 ledger 的节点;
- ledger has many records, called:entry,每个entry都有一个 sequence number,可以根据 ledger + seq 来读取一部分 entry。
- quorum:几个 bookie 组成一个 quorum,通过复制提高可用性。
- data striping:数据块交织写入到各个设备,提高写入的性能。类似 RAID1 的机制。

Striping 很容易就会导致读取者所看到的 log 不一致,因此 BK 引入了 ZK 去保存元数据,并且通过 trimming 机制(BK 称为 reader-initiated ledger recovery)来确保末尾未完整写完整个 quorum 的数据能够被安全删除并且对 reader 不可见。
实现细节
Bookie 的结构
Bookie 是存储节点,具体包含两个模块:
- journal:WAL,同步写,负责保存 writer 的写入操作;
- ledger:包含内存的状态(memtable)、ledger 的索引等,异步写。

理想状况下,journal 和 ledger 应该位于不同的磁盘上,减少他们同时不可用的概率。
BookKeeper 提供的 API
- 创建 ledger
- 向 ledger 新增 entry
- 打开一个 ledger
- 从ledger 读取 entry
- 关闭 ledger 避免后续数据写入
- 删除一个ledger
Ledger 操作
Ledger 创建
一个 ledger 需要由一个 ensemble 来负责,因此创建 ledger 的时候必须指定 ledger 的 quorum 和 ensemble。具备 f+1 个节点的 quorum 可以容忍 f 个节点宕机。
- quorum:写入节点集合。更大的quorum 提供更强的可用性。
- ensemble:striping 所需要的节点总数。更大的 ensemble 提供更大的吞吐。

- quorum 是以 round-robin 的形式分散在整个 ensemble 中。
- quorum 和 ensemble 这些元数据保存在 zookeeper 中。
这里有个问题,当bk客户端尝试读取 entry 的时候,需要确定从哪些bookie组成的quorum 读取,那这个quorum是怎么确定的?

Ledger 关闭
Ledger 关闭是一个原子的操作,会在 ZK 中记录 ledger 最后一个 entry 的 seq。这里ZK 提供的一致性协议非常重要,否则 Bookkeper 的客户端可能会观察到 ledger 的 不一致。
 当 BK 的客户端没有 close 一个ledger 就 crash 怎么办?因此需要一个额外的机制来保证所有 open 的ledger 都能够最终被 close。
当 BK 的客户端没有 close 一个ledger 就 crash 怎么办?因此需要一个额外的机制来保证所有 open 的ledger 都能够最终被 close。
Ledger 的恢复
Ledger 的写入者可能在没关闭 ledger 的时候就 crash 了,这种情况下 entry 的元数据尚未更新到 zk中, ledger 的读取者无法安全地确认 ledger中的最后的 entry 是什么,因此 ledger 需要 恢复操作(recovery)。
当 reader 打开一个 ledger 读取的时候,从 ZK 中获取元数据,同时如果发现这个 ledger 尚未被 close,就触发一个 recovery 流程。
Recovery:确定按所要求的 quorum 写入成功的最后一个 entry,写入到 ZK 中。
如何确认最后一个 entry?可以简单地从 ledger 一次读取所有的entry,重新写入一遍。 为了加速,reader 向 ensemble 中所有的 bookie 询问 此ledger 写入的最新的 entry 的LAC字段(Last Add Confirmed)。然后恢复流程就可以从最高的 LAC 位置开始,而无需读取整个 ledger。
LAC
LAC:Last add confirmed,获取一个 quorum 中最后一个被确认写入的 entry 的 id 对于 单个 bookie 而言,所谓的LAC就是当前 ledger 最后一个写入的 entry 的 entry id。而对于客户端而言,获取quorum 的LAC就是获取整个 quorum 中最大的LAC。
这里比较容易混淆:LAC 应该是维护在 writer 本地的,只是每次写入到 bookie 的时候把它放在 entry 的某个字段中。Quorum 中所有 bookie 的最后一个 entry 的 LAC 最大值,所反映的一定是这个 writer 的 LAC 的最大值,这样一来 LAC 的作用就好理解了,相当于是把 writer 的写入确认水位状态随着 entry 写入到了每一个 bookie中。
这块的介绍可以看 DistributedLog。
Fencing
LAC 只能保证 reader 之间读取的一致性,但是不能避免出现多个 writer。
bookie 检测到某个 ledger 出于 recovery 流程中时,拒绝掉所有这个ledger 写入的请求。
从一个 open 状态的 ledger 读取数据
前述都是基于 reader 只能读取 closed 的 ledger 的前提。但是 reader完全有可能需要读取 open 的ledger(废话。。。),因此 BK 提供了绕过了 recovery 流程的读取API。在这个API 中,为了防止 reader 读取到 transient entry(只在 quorum 中复制了一部分,关闭 ledger 后可能会被 trim 掉的 entry),reader会向bookie 查询 ledger 的 LAC,读取 LAC 以前的 entry 是安全的,因为他们都已经被完整地复制了。
Ledger device:第一版不同的 ledger 有不同的文件,后来改为一个(类似RocketMQ的CommitLog),成为entry log。原因是多个文件的随机写入带来的磁盘寻道、Page cache 的竞争大大降低了写入吞吐。不同 ledger 的 entry 都存储在一个 entry log 中。

对于每个ledger,bookie 在 ledger device 上还维护了一个索引,并且把这个索引 映射 到内存,降低索引构建导致的 IO 开销。
Ledger 的设计主要针对写为主的流量。读的场景下,如果命中了内存中的ledger index,那么只需要一次磁盘 IO,否则需要先从 Ledger index文件找到 entry 所在 entry log 中的位置,然后再去 entry log 中读取entry内容。
源码分析
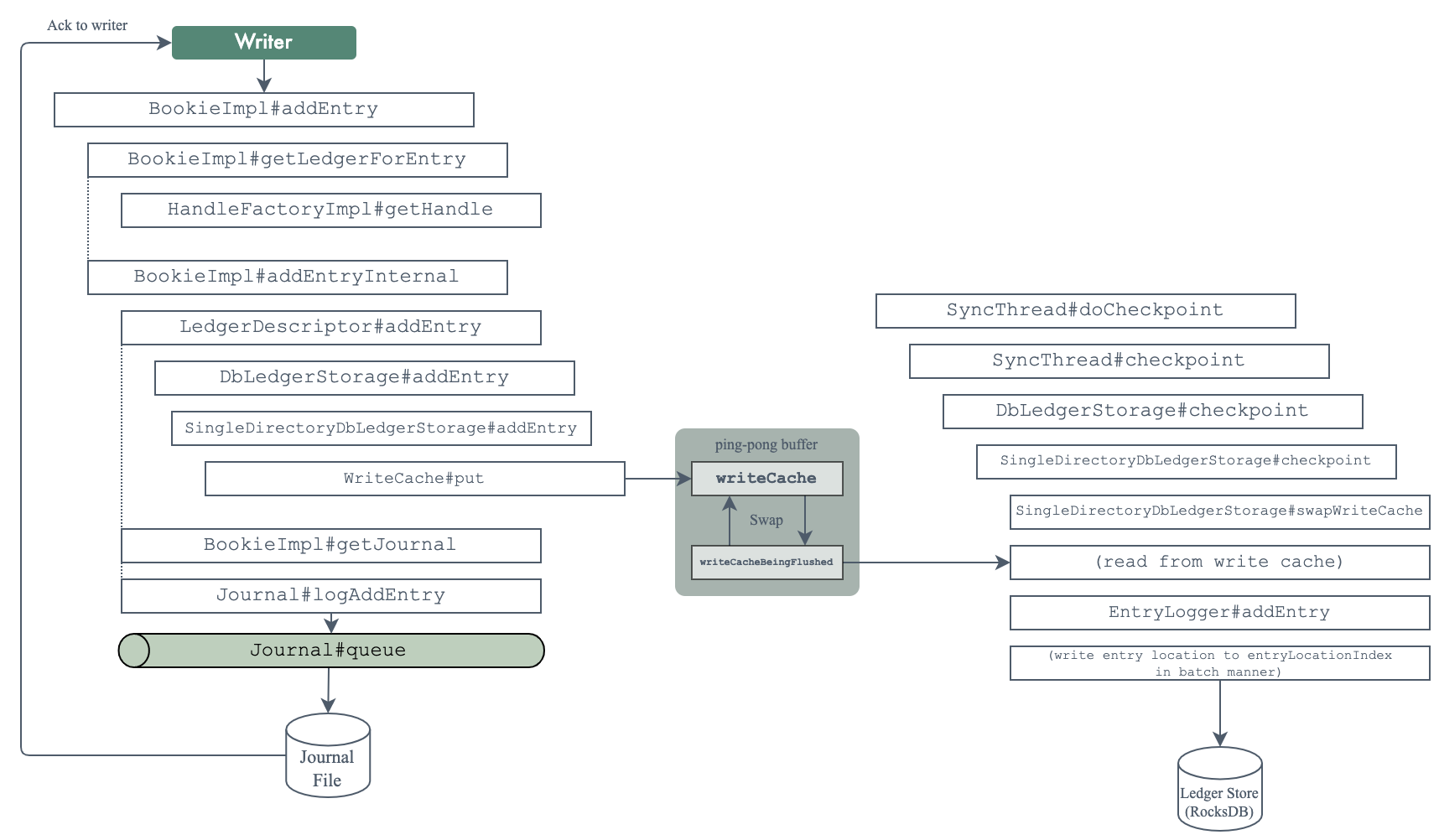
Entry 的写入
Entry 的读取
还是根据 write set 找到负责 entry 的 bookie 列表,然后向这些 bookie 发送读取请求。
Entry 读取的时候可能存在一种特殊情况:读取的 entry 范围一jnkmlxc部分落在一个 ensemble,一部分落在另一个 ensemble,比如下面图中的情况。

为了处理读取散落在不同 ensemble 的 entry 的情况,BookKeeper 每次读取 entry 前都会判断所读取的 entry id 是否出现 ensemble change。

为了避免部分慢节点导致延迟升高,提升读取的性能,BookKeeper 客户端还采用了 speculative read(推测读取)的方式,如果当前读取的 bookie 没有在特定时间内返回数据,那么客户端会立刻尝试向另一个 bookie 发送读取请求,并同时等待两个 bookie 的响应。具体可见 DefaultSpeculativeRequestExecutionPolicy.